1. FeignClient란 ?
Spring Cloud에서 제공하는 선언적 HTTP 클라이언트
Netflix에서 간단하게 HTTP Client를 사용하기 위해 개발한 기술
RestTemplate, WebClient를 쓸 때보다 훨신 가독성있고 편하게 사용 가능
HTTP 기반의 외부 서비스와 통신하기 위한 REST 클라이언트를 간단하게 생성할 수 있도록 도와주는 라이브러리
* WebClient :
Spring webflux의 라이브러리, non-blocking 방식으로 동작 (대용량 트래픽)2. FeignClient의 주요 특징
1. 선언적 API 호출:
FeignClient는 HTTP 요청을 메서드 인터페이스로 선언할 수 있어,
HTTP 요청을 직접 만드는 코드나 RestTemplate을 사용하는 것보다
코드가 간결하고 읽기 쉬운 방식으로 API를 호출 가능
2. 자동 retry 및 로드 밸런싱:
Spring Cloud Feign은 Ribbon과 통합되어 자동으로 로드 밸런싱을 제공하며,
Hystrix와 결합해 장애 처리 및 retry 메커니즘을 지원
3. 템플릿 기반 요청:
@FeignClient 인터페이스에서 메서드를 선언하고, 이를 기반으로 HTTP 요청을 템플릿 방식으로 처리
4. 유연한 커스터마이징:
각종 인터셉터나 오류 처리 메커니즘을 쉽게 추가하여 API 호출 로직을 커스터마이징 가능3. 기본 사용법
1. 의존성추가 :
Spring Cloud OpenFeign
2. OpenFeign 관련 컴포넌트 스캔 활성화 :
@EnableFeignClients 또는 configration 파일 지정된 패키지에서 Feign 클라이언트 인터페이스를 스캔하고, 해당 인터페이스에 대한 구현체를 생성
3. FeignClient 구현 (인터페이스 작성) :
구현체는 크게 Feign의 Default, ApacheHttpClient, OkHttpClient
ApacheHttpClient와 OkHttpClient는 추가적인 의존성을 주입해줘야 사용가능
feign.Client.Default는 Feign에서 기본으로 제공, 의존성 주입 없이 사용가능
Default는 내부적으로 java.net의 HttpUrlConnection을 사용, 가볍고 빠르다는 장점
ApacheHttpClient와 OkHttpClient는 Default 구현체보다 설정할 수 있는 값들이 더 많고, 더 편리한 api들을 제공
4. dto, controller 등 작성
3-1. FeignClient 인터페이스 정의
@FeignClient(name = "user-service")
public interface UserServiceClient {
@GetMapping("/users/{id}")
User getUser(@PathVariable("id") Long id);
@PostMapping("/users")
User createUser(@RequestBody User user);
}3-2. FeignClient 호출
@Service
public class UserService {
@Autowired
private UserServiceClient userServiceClient;
public User getUser(Long id) {
return userServiceClient.getUser(id);
}
public User createUser(User user) {
return userServiceClient.createUser(user);
}
}4. 추가 기능 (errorrecoder, decoder , interceptor, retry)
4-1. RequestInterceptor
Feign 요청을 가로채서 수정하거나, 공통 헤더 , 로깅을 추가하는 등의 작업을 할 수 있습니다.
RequestInterceptor를 사용하여 요청을 인터셉트할 수 있습니다.
* RequestIntercepor : @interface, @Override apply
@Bean
public RequestInterceptor requestInterceptor() {
return new RequestInterceptor() {
@Override
public void apply(RequestTemplate template) {
// 헤더에 인증 토큰 추가
template.header("Authorization", "Bearer " + token);
}
};
}
@FeignClient(name = "user-service", configuration = FeignConfig.class)
public interface UserServiceClient {
@GetMapping("/users/{id}")
User getUser(@PathVariable("id") Long id);
}4-2. ErrorDecoder
Feign 클라이언트를 통해 요청을 보냈을 때 HTTP 응답 코드가 실패한 경우에 처리할 로직을 정의하는 데 사용
spring cloud openfeign은 ErrorDecoder를 통해 응답값이 200이 아닐 경우 에러
400, 404, 500 등의 오류가 발생하면 FeignException을 던지고, 이는 기본적으로 5xx 예외로 처리
public class MyErrorDecoder implements ErrorDecoder {
@Override
public Exception decode(String methodKey, Response response) {
if (response.status() == 404) {
return new NotFoundException("Resource not found");
} else if (response.status() == 500) {
return new InternalServerErrorException("Internal server error");
}
return FeignException.errorStatus(methodKey, response);
}
}
@FeignClient(name = "user-service", configuration = MyErrorDecoder.class)
public interface UserServiceClient {
@GetMapping("/users/{id}")
User getUser(@PathVariable("id") Long id);
}4-3. Decoder
Feign 클라이언트가 서버에서 받은 응답을 객체로 변환하는 역할
기본적으로 JSON을 Java 객체로 변환하기 위해 Jackson을 사용하지만,
다른 포맷(예: XML, YAML 등)을 처리하려면 Decoder를 구현하여 변환 로직을 커스터마이즈
public class MyCustomDecoder implements Decoder {
private final JacksonDecoder jacksonDecoder = new JacksonDecoder();
@Override
public Object decode(Response response, Type type) throws IOException {
// 커스텀 디코딩 로직
if (type.equals(MyCustomType.class)) {
return customDecodeLogic(response);
}
return jacksonDecoder.decode(response, type); // 기본 Jackson 디코더 사용
}
}
@Configuration
public class FeignConfig {
@Bean
public Decoder decoder() {
return new MyCustomDecoder();
}
}
@FeignClient(name = "user-service", configuration = FeignConfig.class)
public interface UserServiceClient {
@GetMapping("/users/{id}")
User getUser(@PathVariable("id") Long id);
}4-4. Retryer
Feign 클라이언트가 요청을 보냈을 때
일시적인 오류(예: 네트워크 오류 등)가 발생하면 자동으로 재시도할 수 있게 해줌,
재시도할 횟수와 대기 시간 등을 설정
public class MyRetryer implements Retryer {
private int attempt = 1;
private static final int MAX_ATTEMPTS = 3;
@Override
public void continueOrPropagate(RetryableException e) {
if (attempt++ > MAX_ATTEMPTS) {
throw e;
}
try {
Thread.sleep(1000); // 재시도 간 대기 시간
} catch (InterruptedException ex) {
Thread.currentThread().interrupt();
}
}
@Override
public Retryer clone() {
return new MyRetryer();
}
}
@Configuration
public class FeignConfig {
@Bean
public Retryer retryer() {
return new MyRetryer();
}
}
@FeignClient(name = "user-service", configuration = FeignConfig.class)
public interface UserServiceClient {
@GetMapping("/users/{id}")
User getUser(@PathVariable("id") Long id);
}
ex. RestTemplate
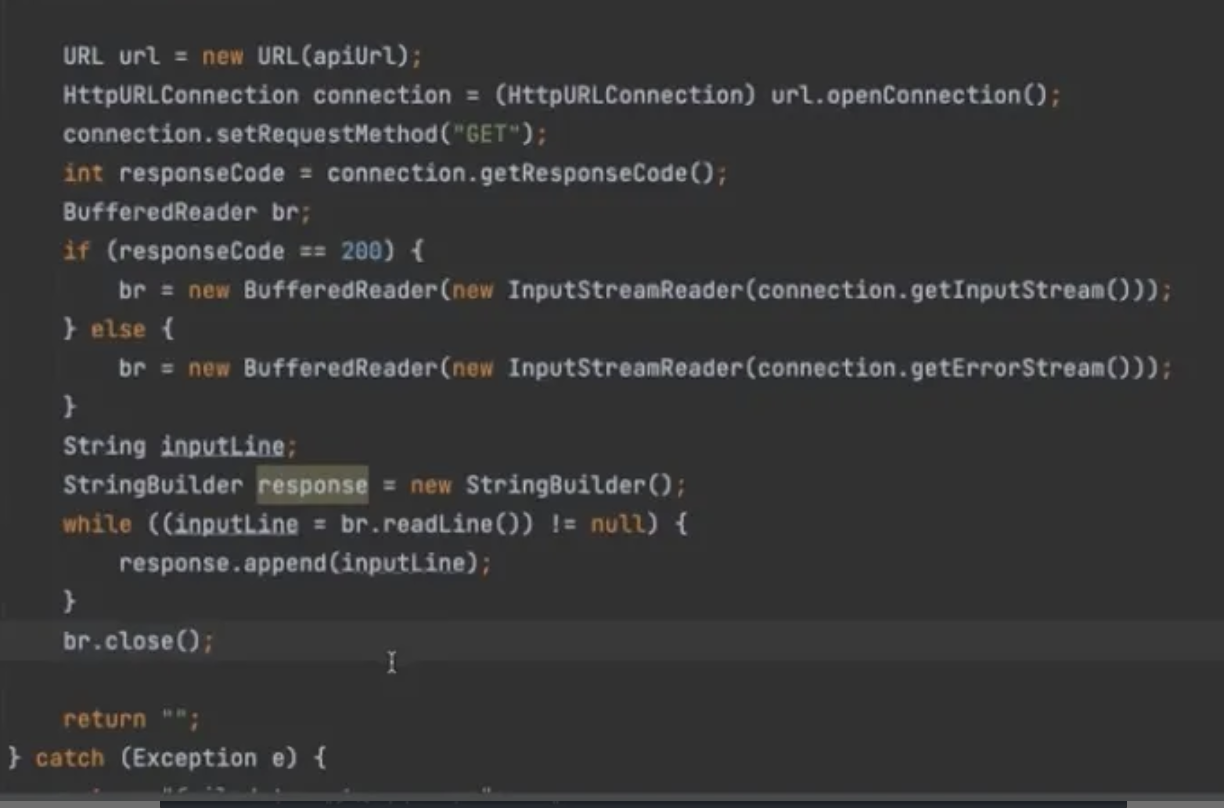
참고 :
https://docs.spring.io/spring-cloud-openfeign/docs/current/reference/html/
https://techblog.woowahan.com/2630/
https://techblog.woowahan.com/2657/
'Spring' 카테고리의 다른 글
| ArgumentResolver (0) | 2025.01.19 |
|---|---|
| 디버깅 모드 (0) | 2025.01.19 |
| 멀티 모듈 (Multi-Module) (0) | 2025.01.17 |
| API(application programming interface), RestAPI (0) | 2023.05.22 |
| 웹 동작방식, HTTP, WAS, Web Server (0) | 2023.05.21 |
